
IICS(CDI) Mapping Designer入門 〜SQL transformation編〜
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
こんにちは、データ事業本部の渡部です。
今回はインフォマティカIDMCのCloud Data Integration(以降、CDI)のSQLトランスフォーメーションについてご紹介します。
SQLトランスフォーメーションはあまり使用頻度が高くなく、そのためあまり深くまでは知らないところもあったため、振り返りを踏まえて過去のトランスフォーメーション紹介記事に倣って記載していきます。
一例ではありますが、過去には以下のようなトランスフォーメーション紹介記事があがっているのでご興味があればご参考ください。
SQLトランスフォーメーションの概要
ざっくりいうと、SQLトランスフォーメーションはマッピングの間にSQLを差し込むことができるトランスフォーメーションです。
DDL・DML・DCLをすべて使用できるので、単純なマッピングだけでは実現できない複雑な要件があるときにより活躍しそうです。
例えば、複数のテーブルを結合したところからデータを取得したい、パラメータを使ったクエリ結果を取得したい、既存SQLを使用したいなど。
使用できるSQLステートメント一覧については、以下で紹介されているのでご参考ください。
基本となるマッピング
今回行うのはS3にあるpurchaseファイルをデータソースとして、同じくS3にtarget-sql-transformationファイルを新規作成してデータを移行するマッピングになります。

データソースpurchase.csvは以下のとおりです。
"userId","purchaseAmount","productId"
"1","5000","A001"
"2","3500","B002"
"3","12000","C003"
"4","8750","A004"
"5","2300","B005"
SQLトランスフォーメーションの組み込み
SQLトランスフォーメーションを左メニューからドラッグ&ドロップして、ソースとターゲットの間に配置します。
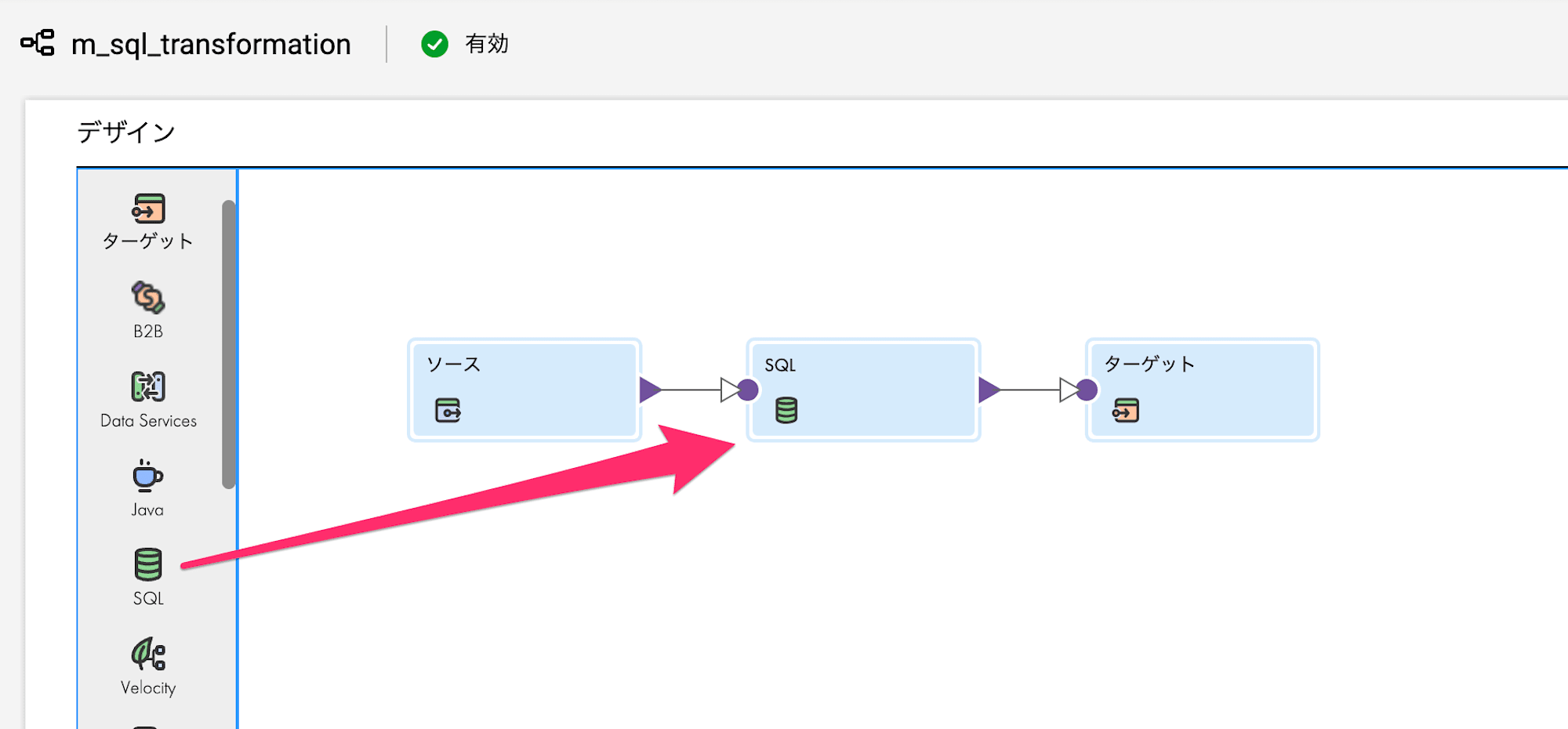
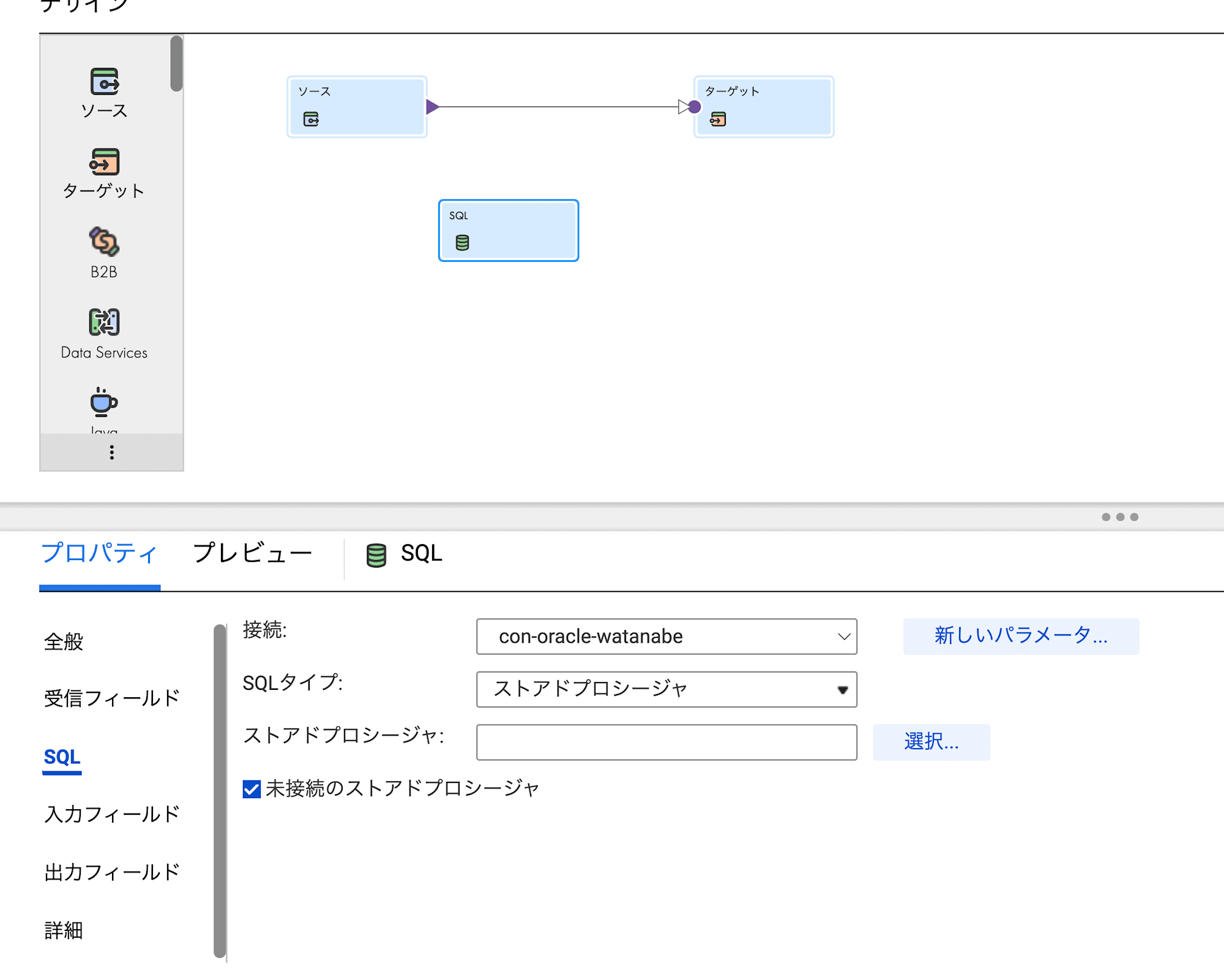
SQLトランスフォーメーションのプロパティ
SQLトランスフォーメーションを選択すると各プロパティが設定できますので細かく見ていきます。
「全般」「受信フィールド」は他のステップと共通なので割愛します。
SQL
SQLプロパティでは、SQLタイプとそのクエリを設定します。
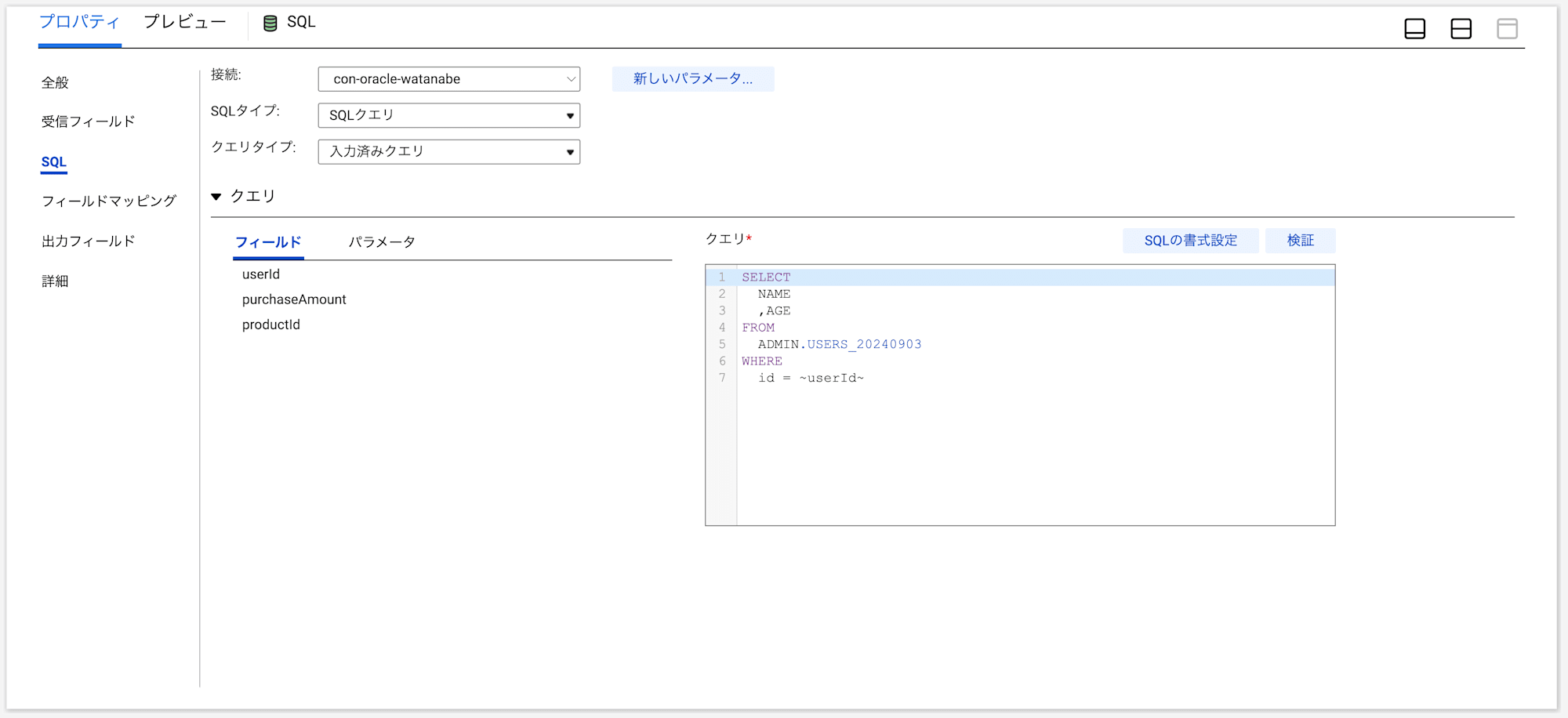
- 接続:SQLを実行したいDBを選択します。
- SQLタイプ:
ストアドプロシージャ・ストアドファンクション・SQLクエリから選択します。
今回はSQLタイプとしてSQLクエリを選択したので、以降はそちらに関する設定を記載します。
- クエリタイプ:
入力済みクエリ・保存済みクエリから選択します。 - クエリ:実際にクエリを記載します。左側にはクエリに記載できるフィールドとパラメータが表示されています。
入力済みクエリは画像のとおり、マッピングに直接クエリを記載するもので、保存済みクエリはInformaticaのコンポーネントであらかじめ作成した保存済みクエリを呼び出すものとなります。
SQLは以下のとおり記載しました。
ソースからのフィールドをクエリに渡す場合は、フィールド名を「~」で囲む必要があります。
SELECT
NAME
,AGE
FROM
ADMIN.USERS_20240903
WHERE
id = ~userId~
フィールドマッピング
SQLタイプでSQLクエリを選択した際は表示されません。
引数設定が必要なストアドプロシージャ・ストアドファンクションを選択した際に設定するものです。
出力フィールド
後続のトランスフォーメーションに連携するフィールドについて設定します。
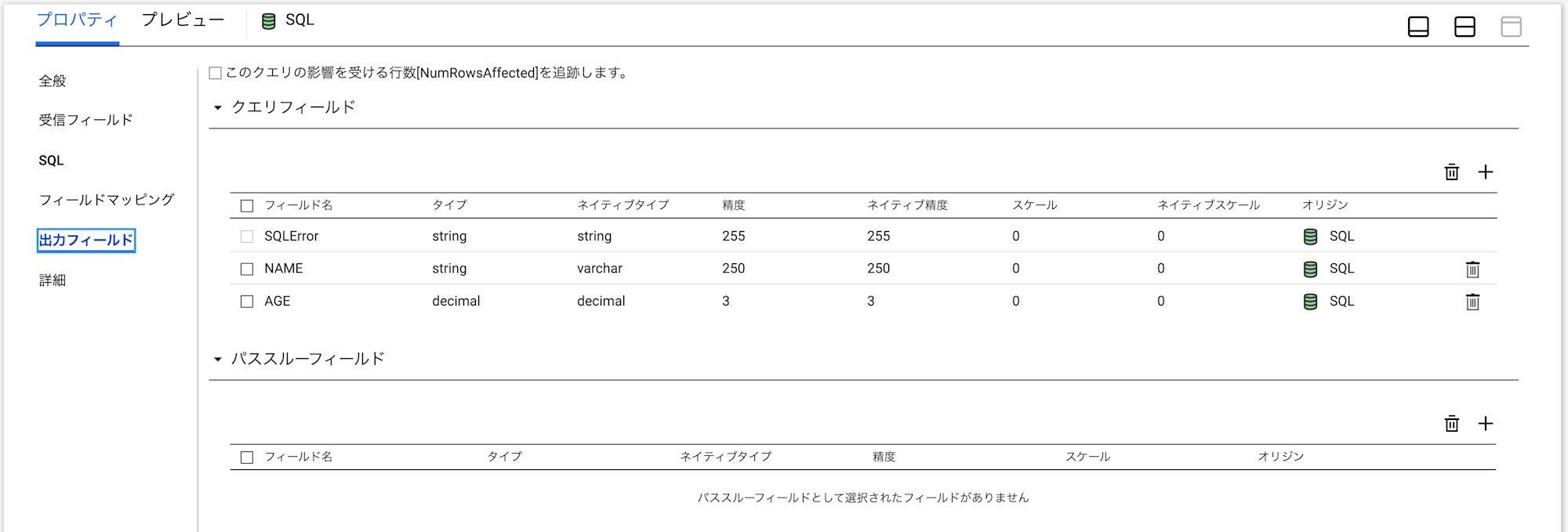
- このクエリの影響を受ける行数[NumRowsAffected]を追跡します:InsertやUpdate・Deleteした行数をフィールドとして出力させたい場合に設定します。
- クエリフィールド:SQLトランスフォーメーションとして出力させるフィールドを定義します。例えばSELECT句の項目を設定します。
- パススルーフィールド:SQLトランスフォーメーション前のフィールドのうち、後続に渡したいフィールドを設定します。
クエリフィールドについて、デフォルトでSQLErrorというフィールドが出力されるようになっています。
こちらはSQLのエラー時にそのエラー内容が格納されるフィールドとなります。
クエリがSELECTの場合は、項目を設定する際にSELECT句の項目の順番どおりに出力フィールドを手動で設定する必要があります。出力フィールドの方が少ない場合はエラーとなってしまいます。
なおクエリタイプとして保存済みクエリを使用する場合は、Informaticaが自動的に出力フィールドを表示してくれるようなので、保存済みクエリの使用が推奨です。
詳細
追加のプロパティを設定します。
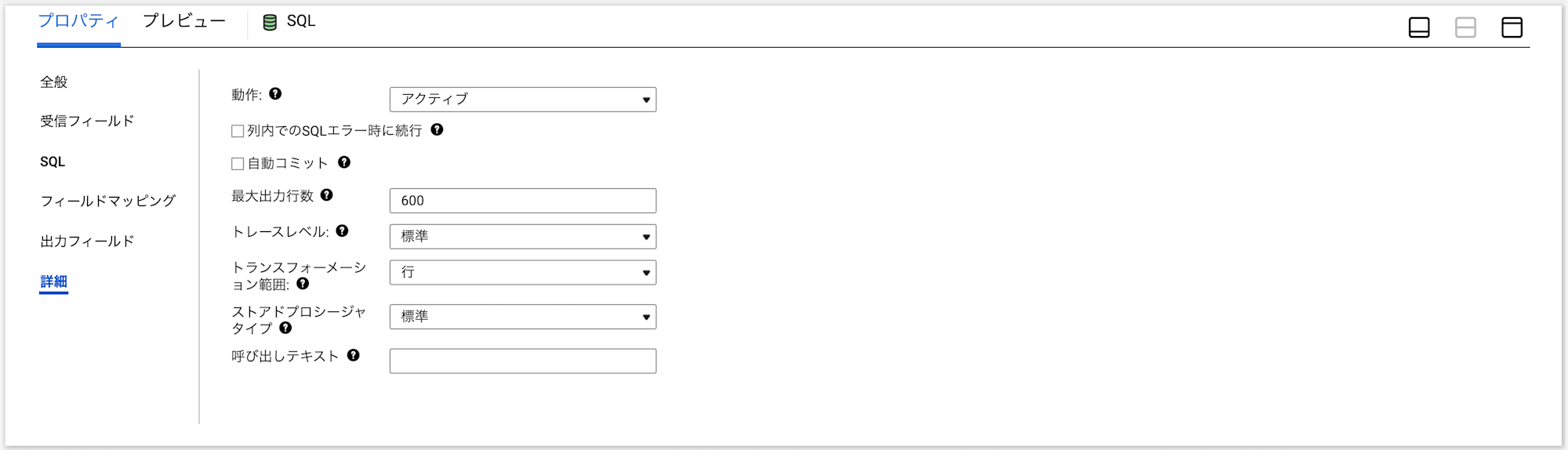
- アクティブ:トランスフォーメーションの動作タイプ
アクティブ・パッシブが設定できます。トランスフォーメンションに対して1行の入力行につき0行以上の行を返すのがアクティブで、0行もしくは1行の行を返すのがパッシブとなります。 - 列内でのSQLエラー時に続行:クエリ内に複数のSQLが存在しSQLエラーが発生した際に、後続のSQLを続行させる場合に設定します。なお誤訳で列内ではなく行内と思われます。
- 自動コミット:文字通りSQLの処理が終わった時に自動コミットするかどうかの設定です。
- 最大出力行数:SQLのSELECTから返る最大行数の設定です。制限しない場合は0を設定します。
- トレースレベル:セッションログの粒度を設定できます。
- トランスフォーメーション範囲:トランスフォーメーションが一度に扱う入力データの範囲を設定します。
行・トランザクション・すべての入力が選択できて、行がデフォルトです。 - ストアドプロシージャタイプ:ストアドプロシージャの呼び出しタイミングについて、ターゲットロードの前or後、通常、ソースリードの前or後の5つのどれかを設定します。
- 呼び出しテキスト:ストアドプロシージャを呼び出し、かつマッピングパイプライン上にSQLトランスフォーメーションを含めない未接続モードを使用する際に、ストアドプロシージャ名と引数を記載して呼び出す設定です。
未接続モード
SQLトランスフォーメーションはLookUpトランスフォーメーションと同じく、マッピングパイプライン上に含めずに未接続モードで使用することが可能です。
未接続モードで呼び出せるSQLタイプはストアドプロシージャです。
ターゲット
出力したいフィールドを設定します。
今回は以下の3項目を設定しました。

実行してみると
今回SQLトランスフォーメーションで呼び出すテーブルUSERS_20240903のデータは以下のようになっています。
ID,NAME,AGE,ADDRESS
1,Yamazaki Kana,56,41-20-3 Shimo-Yoshiha
2,Suzuki Yui,,4-1-13 Shibancho
3,Kobayashi Taichi,,20-9-13 Marunouchi
4,Yamashita Yosuke,51,9-5-5 Yumiyama
5,Ito Akemi,67,23-22-16 Nishikanda
6,Kato Yumiko,39,
7,Yamamoto Yui,52,33-18-6 Misugi
8,Takahashi Sotarou,52,36-2-12 Katsudoki
9,Yamamoto Osamu,65,25-8-11 Matsuura-cho
10,Yamamoto Maaya,28,42-18-20 JP Tower
11,Sasaki Asuka,38,41-8-16 Kitakano
12,Sato Takuma,66,28-27-20 Minami-Machi
13,Suzuki Kan,66,
14,Nakagawa Kumiko,38,34-13-17 Hosodake
15,Nakamura Kyosuke,31,11-15-8 Ashikoshi-cho
作成したマッピングを実行すると、出力結果は以下のとおりになりました。
"SQLError","NAME","AGE"
"","Yamazaki Kana","56"
"","Suzuki Yui",""
"","Kobayashi Taichi",""
"","Yamashita Yosuke","51"
"","Ito Akemi","67"
ソースのcsvとSQLをもとにすると、idが1~5のNAMEとAGEが出力されているため想定とおりです。
以上、どなたかのご参考になれば幸いです。







